Anthropic's Rapid Response: A New Approach to Mitigating LLM Jailbreaks
Nov 14, 2024
Tom Keldenich
Rapid Response is a new strategy created by researchers at Anthropic aimed at reducing the risks associated with Large Language Models (LLMs). This approach focuses on addressing vulnerabilities linked to jailbreaking, where attackers exploit LLMs to generate harmful outputs. The research represents a shift from traditional static defenses to a more dynamic method that allows for quick adaptation against emerging threats.
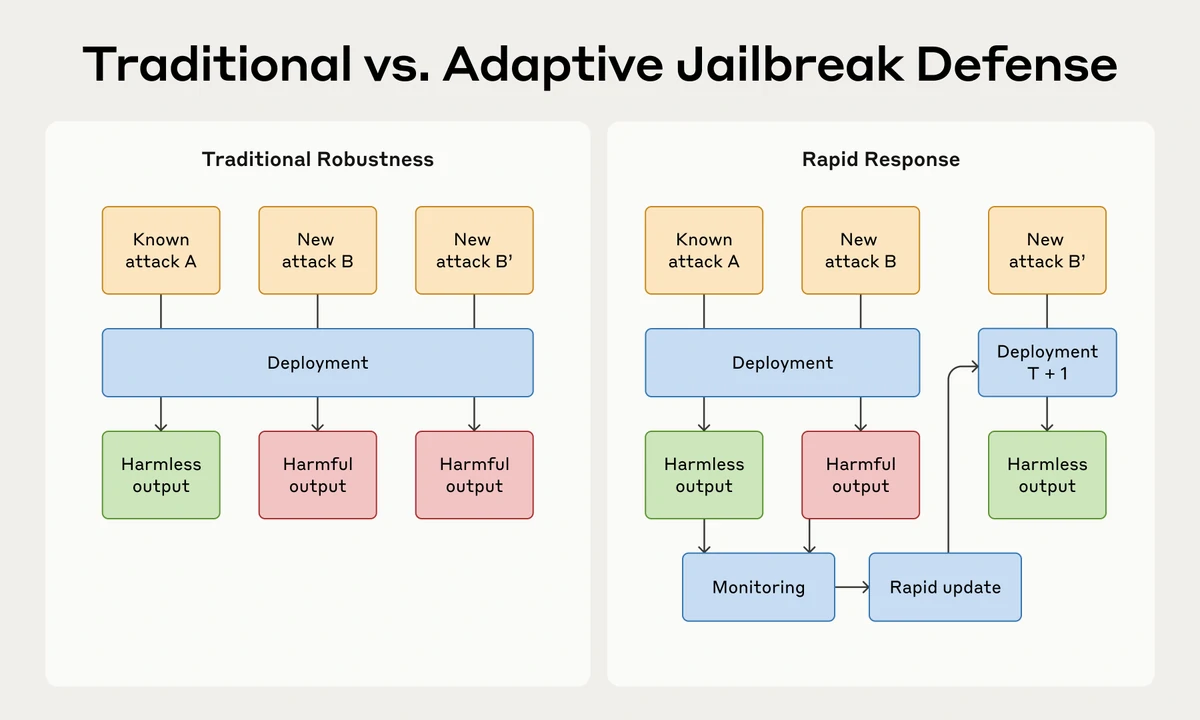
Traditional defenses aimed for robust systems that could resist known threats. However, these methods often fail quickly against new attacks. This situation poses significant challenges for ensuring the safety of powerful LLMs in real-world applications.
To measure the effectiveness of this method, researchers developed RapidResponseBench, a benchmark to evaluate various rapid response techniques against specific jailbreak strategies.
The most effective method identified was fine-tuning an input classifier with these proliferated examples. This resulted in a substantial decrease in attack success rates—over 240-fold on in-sample examples and more than 15-fold on out-of-sample instances—even with limited exposure.
Moreover, effective organizational protocols for rapid updates in defense systems are essential to ensure safety.
However, it might fall short in high-stakes cases that allow for rapid exploitation of vulnerabilities that could lead to severe consequences.
In conclusion, Rapid Response represents a transformative solution for addressing jailbreaking challenges. Findings from RapidResponseBench demonstrate that this model can offer effective, swift defenses against evolving threats.
As researchers continue to explore threat modeling and real-time detection, this approach could enable the safer deployment of advanced language models in various settings.
Alwin Peng, Julian Michael, Henry Sleight, Ethan Perez, Mrinank Sharma (2023). "Rapid Response: Mitigating LLM Jailbreaks with a Few Examples." arXiv:2411.07494v1 [cs.CL].
Large Language Models Adversarial Robustness in AI Automated Red-Teaming Techniques
Anthropic. (2023). AI Safety Initiatives. OpenAI. (2023). OpenAI safety practices.
RapidResponseBench GitHub Repository Understanding Large Language Models on Wikipedia Principles of Adversarial Machine Learning
Introduction to Jailbreaking and Its Challenges
Understanding Jailbreaking
Jailbreaking involves taking advantage of weaknesses in LLMs to coax out harmful or restricted responses. As these models become more advanced and widespread, the risks associated with jailbreaking grow.Traditional defenses aimed for robust systems that could resist known threats. However, these methods often fail quickly against new attacks. This situation poses significant challenges for ensuring the safety of powerful LLMs in real-world applications.
Limitations of Current Defenses
Many existing techniques designed to enhance LLM robustness have not reached perfect security. New defenses are often bypassed shortly after they are released, highlighting the inadequacy of static methods for ensuring safety.Jailbreak Rapid Response: An Innovative Strategy
Conceptual Framework
The proposed Jailbreak Rapid Response introduces a new way to handle threats. Rather than striving for perfect defenses, this approach focuses on promptly taking action once jailbreak attempts are detected.To measure the effectiveness of this method, researchers developed RapidResponseBench, a benchmark to evaluate various rapid response techniques against specific jailbreak strategies.
Methodology and Evaluation
The framework assesses how well rapid response methods adapt defenses based on a small number of jailbreak attacks. One of the key techniques examined is jailbreak proliferation, which involves generating additional examples from observed jailbreaks to improve a system's adaptability.The most effective method identified was fine-tuning an input classifier with these proliferated examples. This resulted in a substantial decrease in attack success rates—over 240-fold on in-sample examples and more than 15-fold on out-of-sample instances—even with limited exposure.
Assessing the Effectiveness of Rapid Response Techniques
Key Findings from RapidResponseBench
Researchers tested five baseline methods focusing on input-guarded LLMs. Results indicated that rapid response approaches effectively reduced the success rates of jailbreak attempts, particularly with Guard Fine-tuning, which showed impressive adaptability without significantly increasing refusals for harmless queries.Proliferation Model Advantage
The study underscored the importance of the jailbreak proliferation model, showing that increased capability and more generated examples led to better defense efficiency. This emphasizes the value of using comprehensive data augmentation techniques for real-time threat responses.Implications for Future AI Safety Measures
Timely Detection and Adaptation
For rapid response methods to succeed, teams must swiftly detect jailbreak attempts. Suggestions include encouraging responsible disclosure and establishing monitoring systems to identify vulnerabilities promptly.Moreover, effective organizational protocols for rapid updates in defense systems are essential to ensure safety.
Evaluating Risk Mitigation Scenarios
The overall effectiveness of rapid response strategies also relies on understanding specific scenarios of misuse. Rapid response could work better in low-stakes situations, where quick detection and remediation can prevent significant harm.However, it might fall short in high-stakes cases that allow for rapid exploitation of vulnerabilities that could lead to severe consequences.
Conclusion
In conclusion, Rapid Response represents a transformative solution for addressing jailbreaking challenges. Findings from RapidResponseBench demonstrate that this model can offer effective, swift defenses against evolving threats.
As researchers continue to explore threat modeling and real-time detection, this approach could enable the safer deployment of advanced language models in various settings.